Introduction
Prospecter is an open source implementation of “prospective search” (also called standing search or query subscription). This is basically regular search inverted. Instead of taking a user query and running it against a collection of pre-indexed documents, queries are collected and run against documents as they arrive.
Classic examples include Google Alerts and real estate websites offering saved searches, that will inform you if new real estate listings matching your search are posted. Implementing a system like that in a web or mobile project usually results in systems that do not scale well and are hard to maintain.
For regular search very few people implement the search algorithms themselves but instead use Lucene, Elasticsearch, solr or similar software packages. So why should you do it for prospective search?
Why Prospecter
Currently there aren’t that many open source implementations for this kind of search. The most widely used implementation is probably Elasticsearch with it’s percolator feature. The percolator feature “suffers” from the fact that it does not scale as well as the regular search feature. It is also a little awkward to use, probably because it was added as an afterthought.
Google AppEngine offers a prospective search feature which is closed source and still marked experimental.
So after thinking about how to do prospective search properly and reading several papers on the topic, I decided it was a good idea to implement a software dedicated to prospective search. My goal is to have a lightweight server that is easy to configure and speaks JSON. Similar to Elasticsearch it should be “batteries included”.
And obviously it has to be extremely fast.
Implementation Status
At the moment all crucial features are implemented and work. Prospecter can run as a server exposing a simple JSON REST interface. Available operations are: index query, delete query, match document.
An index can contain fields of the following types:
- Text: For fulltext search
- String: Exact match string
- Integer: Exact match and “greater than” and “less than” searches
- Long: Exact match and “greater than” and “less than” searches
- DateTime: Exact match and “greater than” and “less than” searches
- Double: Exact match and “greater than” and “less than” searches
- Geo: Match documents that lie within a bounding box of a latitude, longitude and radius
The HTTP server is very lightweight and it is very easy to build custom applications that deal with the index directly skipping all networking. This can be useful for very high throughput or indexing a lot of queries at once.
Performance
Performance is looking very good already. The diagram shows the average matching time in ms for the same document with increasing indexed queries. In this case, matching was done on a single text field.
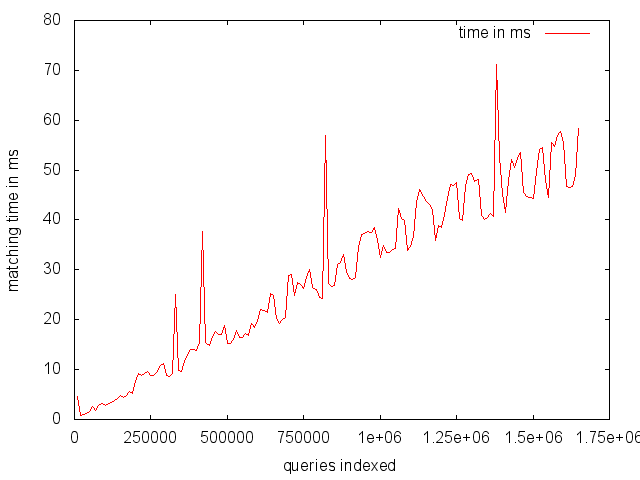
The measurements were done on a MacBook Pro 13 with an i5 2.6 GHz and 8GB RAM. Only the matching time was measured, not including any networking overhead. The indexed queries were from the AOL search query logs and the document was a news article containing 909 words. After every 10.000 indexed queries the test document was matched 10 times and the average matching time calculated. Memory consumption increased steadily up to 300 MB with 1.650.000 queries indexed.
Other index types have mostly been tested with random data which does not say a lot about real world use cases. The geo index filled with 1.000.000 random bounding box searches spread over Germany takes about 500ms to complete, resulting in 14k matches on average. The geo index has probably huge potential for tuning, as there are several data structures known that specialize in indexing spatial data.
Limitations
- All index data has to fit into main memory
- Currently there is no built-in mechanism to search for exact matches in text i.e. “foo bar” would match all documents containing those two words in any order.